Reactive monitoring jumps into action after a problem hits. Teams wait for failures or breaches. Then they respond quickly to fix them. This straightforward method still powers many IT operations, manufacturing lines, and safety programs. We think it deserves attention because plenty of organizations depend on it every single day, especially when budgets stay tight or systems run stable.
Key Takeaways:
- Reactive monitoring waits for issues to occur and then triggers alerts based on crossed thresholds, making it simple and cost-effective to implement initially;
- It excels at quick response, targeted fixes, and learning from real incidents, which helps reduce repeat problems over time;
- Common examples include server disk alerts, slow database queries during peak traffic, and sudden equipment vibration spikes in plants;
- Compared to proactive monitoring, reactive approaches accept some downtime but require fewer resources upfront and suit stable or legacy systems well;
- Combining both creates the best coverage: reactive acts as a safety net while proactive prevents most issues before they escalate;
- Success depends on fast team response, clear documentation, and regular reviews of alerts and incidents;
- Many organizations still rely on reactive monitoring for its practicality, especially smaller teams or operations with predictable failure patterns;
- Hybrid models often yield the strongest long-term results by balancing immediate action with forward-looking prevention.
What Is Reactive Monitoring
Reactive monitoring activates only once something goes wrong. It relies on predefined thresholds. When a metric crosses the line, alerts fire off. Engineers or technicians rush to diagnose and repair.
The setup stays simple. You pick key indicators like server CPU usage, disk space, network latency, or equipment vibration. Tools watch these constantly. Silence rules until a limit breaks. Then notifications hit email, SMS, or dashboards.
Key Characteristics of Reactive Monitoring
- Triggered by actual incidents or threshold violations;
- Focuses on rapid detection and resolution after the event;
- Uses basic threshold-based alerts rather than complex pattern analysis;
- Generates logs and records for post-incident review;
- Requires minimal upfront configuration compared to advanced systems.
This approach works well in environments where failures follow known patterns. A database runs out of space overnight. The alert pings the team. They clear logs and expand storage before a total crash. Response speed decides the damage level. Fast teams contain issues. Slower ones watch small glitches grow bigger.
In safety management, reactive monitoring reviews accidents, near-misses, or ill-health cases after they occur. Investigators collect facts. They examine what failed in the controls. Changes get implemented to stop repeats. These lagging indicators provide concrete evidence of weaknesses.
Honestly, reactive monitoring accepts some disruption first. Downtime occurs. Users feel the impact. Yet quick action often limits how far problems spread. Many smaller teams or legacy setups prefer it because training stays light and costs remain low at launch.
Common Tools and Techniques
- Threshold-based alerting systems;
- Log analyzers that scan for error codes;
- Basic application performance monitors;
- Incident ticketing platforms linked to alerts.
According to our analysts, reactive monitoring shines when the main goal is fast restoration rather than total prevention.
Benefits of Reactive Monitoring
Reactive monitoring delivers clear advantages in the right contexts. Lower initial investment stands out right away. You avoid heavy spending on AI models, long data training, or constant baseline building. Just define limits and start watching.
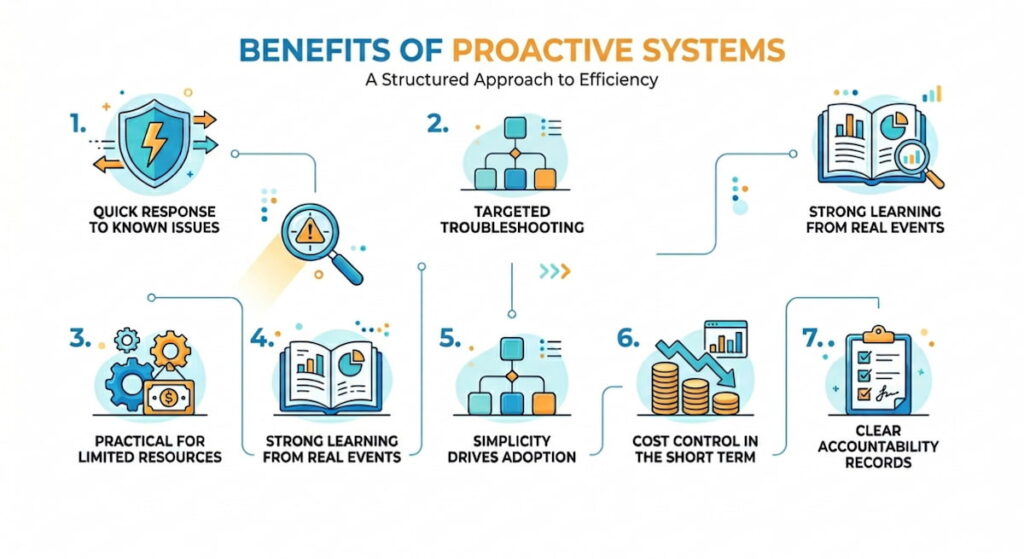
Main Benefits
- Quick response to known issues — Problems get spotted soon after they start. Service restores faster in many cases;
- Targeted troubleshooting — Alerts point directly at the broken metric. Teams skip broad guessing and focus energy where it hurts;
- Practical for limited resources — Smaller organizations or stable systems manage it without large dedicated teams;
- Strong learning from real events — Each incident adds useful data. Root cause analysis reveals gaps. Repeat problems often drop after documentation improves;
- Simplicity drives adoption — Staff understand it fast. No deep data science needed. Green means calm. Red means act now;
- Cost control in the short term — Pay mainly for fixes when needed instead of ongoing advanced monitoring overhead;
- Clear accountability records — Timestamps and logs show exactly who responded and how. Management tracks performance easily.
In manufacturing plants, reactive monitoring catches sudden machine stops. Maintenance crews repair fast. Production resumes without hours of idle time when sensor budgets stay limited.
Safety teams gain too. Incident reports after events drive better procedures or equipment upgrades. One investigated slip can prevent future injuries across shifts.
We think the quiet win sits in straightforward operations. Teams stay ready for surprises without constant alert fatigue from tiny anomalies. According to our data, well-run reactive setups still deliver reliable uptime for many mid-sized environments.
Of course it has limits. Unplanned outages disrupt schedules. Stress rises during off-hours calls. Yet these trade-offs feel manageable when failure rates stay predictable.
Example of Reactive Monitoring
Real-world cases show how reactive monitoring handles daily pressures effectively.
E-commerce Website During Peak Sales
Traffic explodes on a promotion day. The checkout page suddenly slows. Customer complaints roll in. The monitoring tool detects database query times exceeding five seconds. Alert fires to the operations team.
Engineers investigate immediately. They find a locked table from an inefficient query. They kill the process and rewrite the code snippet. Site performance returns within minutes. Lost sales stay minimal instead of turning into major revenue hits.
Industrial Pump in a Chemical Plant
Vibration levels spike after a bearing begins to seize. The threshold alert triggers right away. Technicians isolate the pump quickly. They replace the faulty part during a short planned pause. The entire production line avoids a full shutdown.
Server Disk Space Crisis
A critical server fills up overnight. Reactive monitoring catches the 95% full warning. The team clears old logs and adds storage capacity before applications fail completely. Users notice almost nothing.
Database Performance Issue
During busy hours a slow query alert activates. Developers trace the inefficient join statement. They optimize it on the spot. Response times snap back to normal. No widespread slowdown reaches end users.
These examples highlight a pattern. Issues surface. Teams respond. Damage gets contained when people stay alert and processes stay clear. Reactive monitoring proves practical across IT, manufacturing, and operations.
Proactive Monitoring Vs Reactive Monitoring
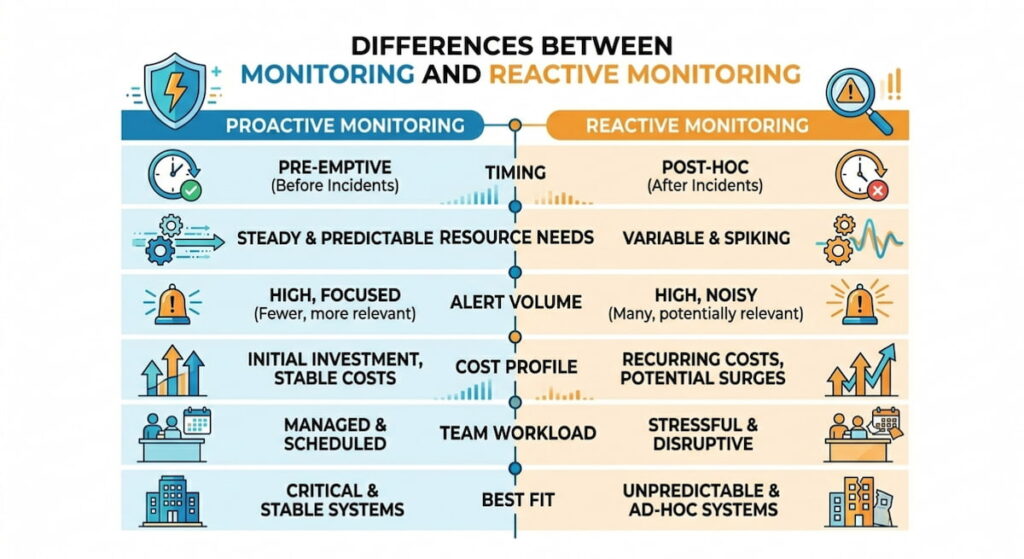
Proactive monitoring scans continuously for early signs of trouble. It builds normal behavior profiles. Small drifts trigger warnings long before users notice. Reactive monitoring waits until thresholds break or actual failures occur.
Core Differences
- Timing: Proactive acts before impact. Reactive responds after problems start;
- Resource needs: Reactive stays lightweight with basic thresholds. Proactive demands more data storage, analysis power, and setup time;
- Alert volume: Reactive usually produces fewer notifications since it waits for clear breaches. Proactive risks more noise unless tuned well;
- Cost profile: Reactive looks cheaper initially but can accumulate emergency repair bills. Proactive investing early yet often reduces total long-term expenses;
- Team workload: Reactive keeps crews in response mode with surprise calls. Proactive allows more planned work during normal hours;
- Best fit: Reactive suits stable systems with predictable failures. Proactive fits complex, fast-changing environments where small issues cascade quickly.
Many modern platforms blend elements of both. You set reactive alerts for critical hard limits while adding proactive trend watching on top.
We think neither approach wins universally. Legacy setups often run fine with strong reactive foundations. Cloud-scale operations usually need proactive layers to handle growth. According to our analysts, purely reactive teams report higher average downtime per incident over time.
Combining Proactive and Reactive Monitoring
Smart organizations mix both methods for balanced coverage. Reactive monitoring serves as the reliable safety net. It catches whatever proactive systems miss. Proactive handles most prevention work.
How to Effectively Combine Proactive and Reactive Monitoring
- Start with solid reactive basics — Set clear thresholds on vital metrics and build fast escalation paths;
- Layer proactive capabilities — Create behavior baselines and watch for gradual deviations;
- Feed reactive incident data back into proactive models — Repeated issues teach the system to flag similar risks earlier;
- Use unified dashboards — Show active alerts alongside early warnings so priorities stay obvious;
- Automate where possible — Let reactive alerts trigger simple fixes like restarts. Route proactive signals to scheduled maintenance;
- Test on critical assets first — Measure downtime and response times before and after adding the mix;
- Review regularly — Check alert accuracy and adjust rules based on real outcomes each month.
In manufacturing, sensors feed both systems. Sudden failures trigger immediate reactive response. Gradual wear patterns alert proactive teams for planned replacements during normal shifts.
Security operations benefit strongly. Reactive catches active breaches through known signatures. Proactive spots unusual patterns that suggest early reconnaissance.
Cloud teams gain huge value too. Reactive handles sudden zone failures or spikes. Proactive predicts capacity needs before costs explode.
Hybrid setups deliver the strongest results for most mature environments. Pure reactive leaves gaps. Pure proactive still needs backup for unknown surprises.
Implementation needs patience. Begin small on one key application. Train staff on handling urgent reactive tickets differently from proactive investigations. Clear playbooks prevent mix-ups.
We think regular performance reviews keep the balance healthy. Tools like Prometheus with Alertmanager or commercial platforms support hybrid modes without massive custom work.
Reactive monitoring remains a practical, battle-tested choice. It delivers fast responses when failures strike. Benefits appear clearest in simplicity and lower starting costs. When paired thoughtfully with proactive elements, it creates robust operations that handle both expected and unexpected events. Start where your biggest pains sit. Measure results honestly. Adjust as your environment grows. This guide equips you with the structure to decide what fits best.
